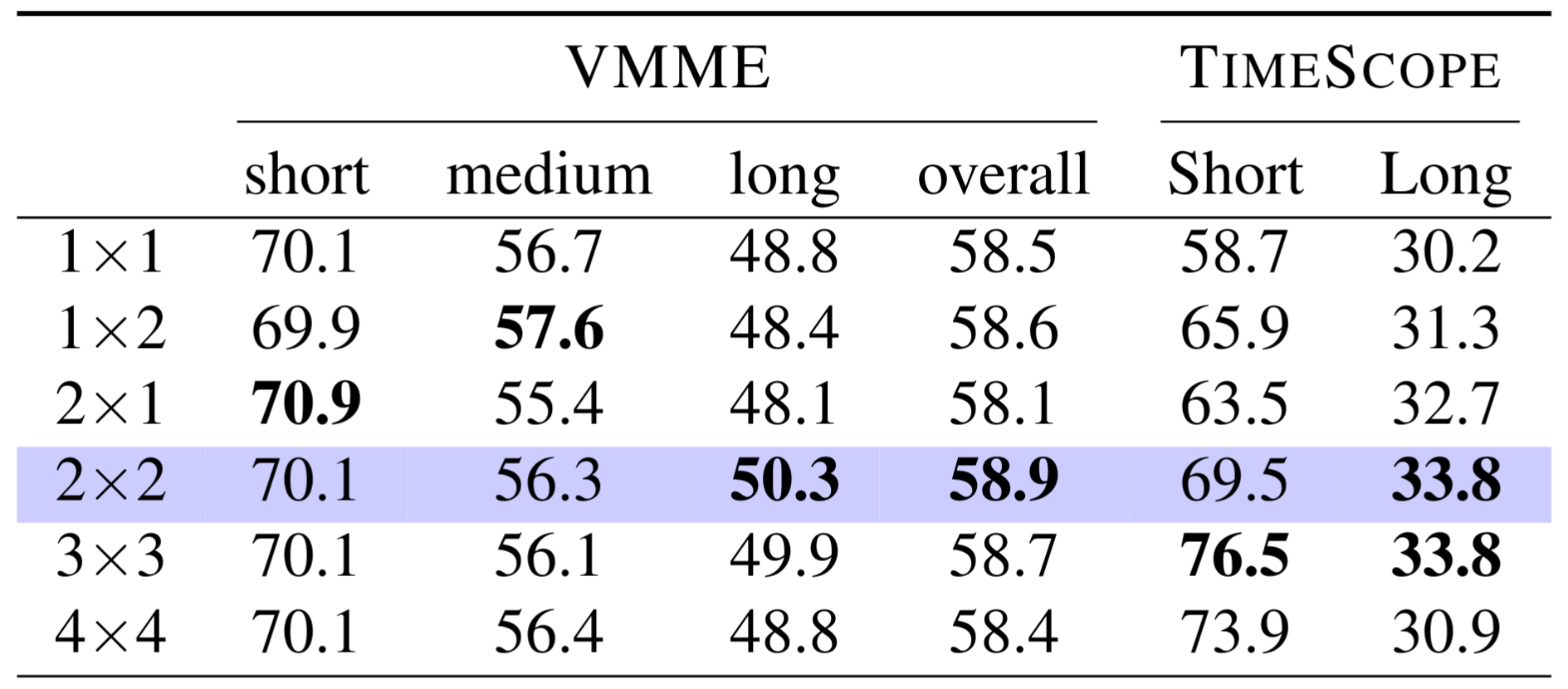
Performance evaluation across multiple benchmarks demonstrating the benefits of our approach. Best results within each model pair are in bold.
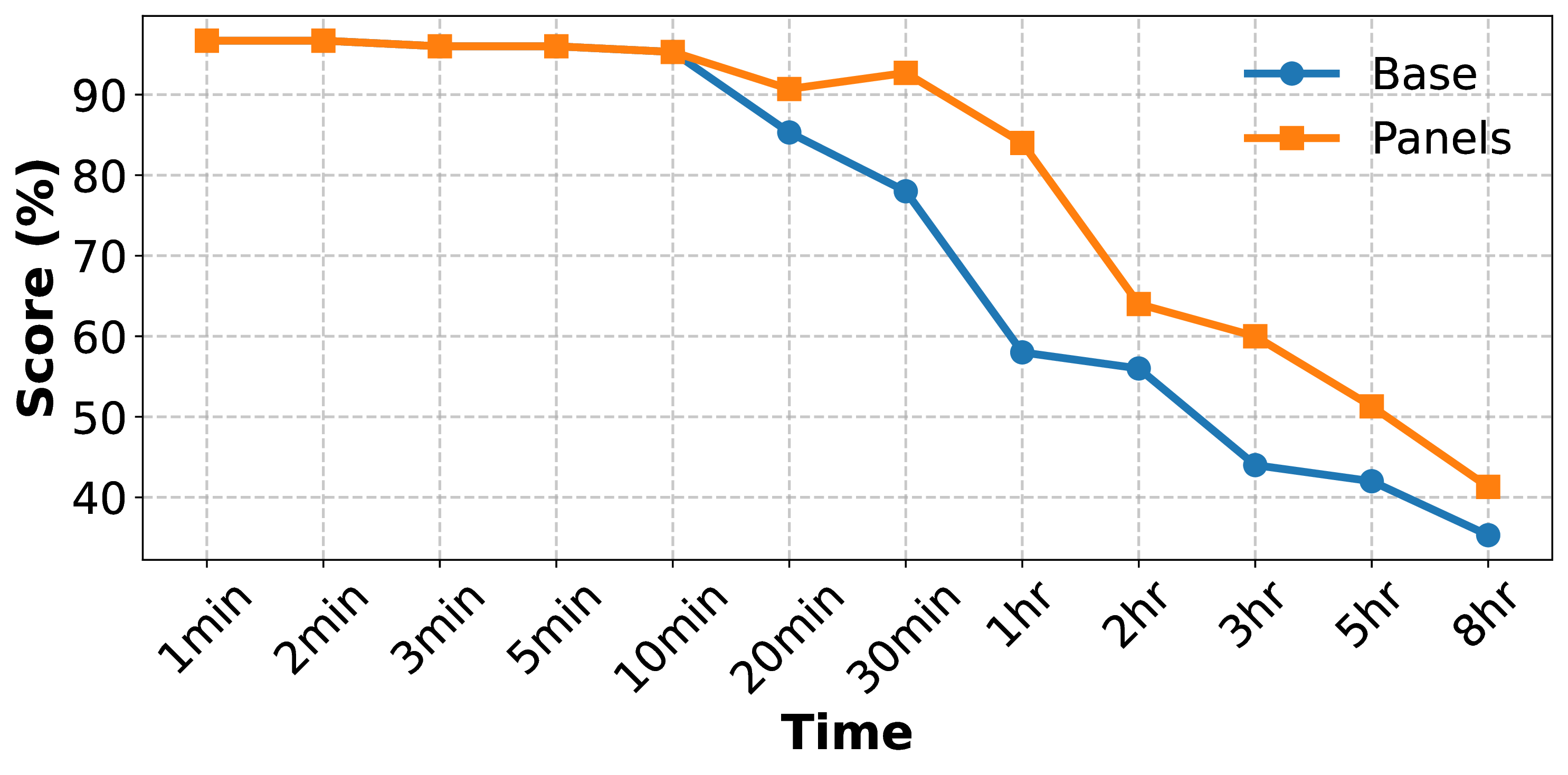
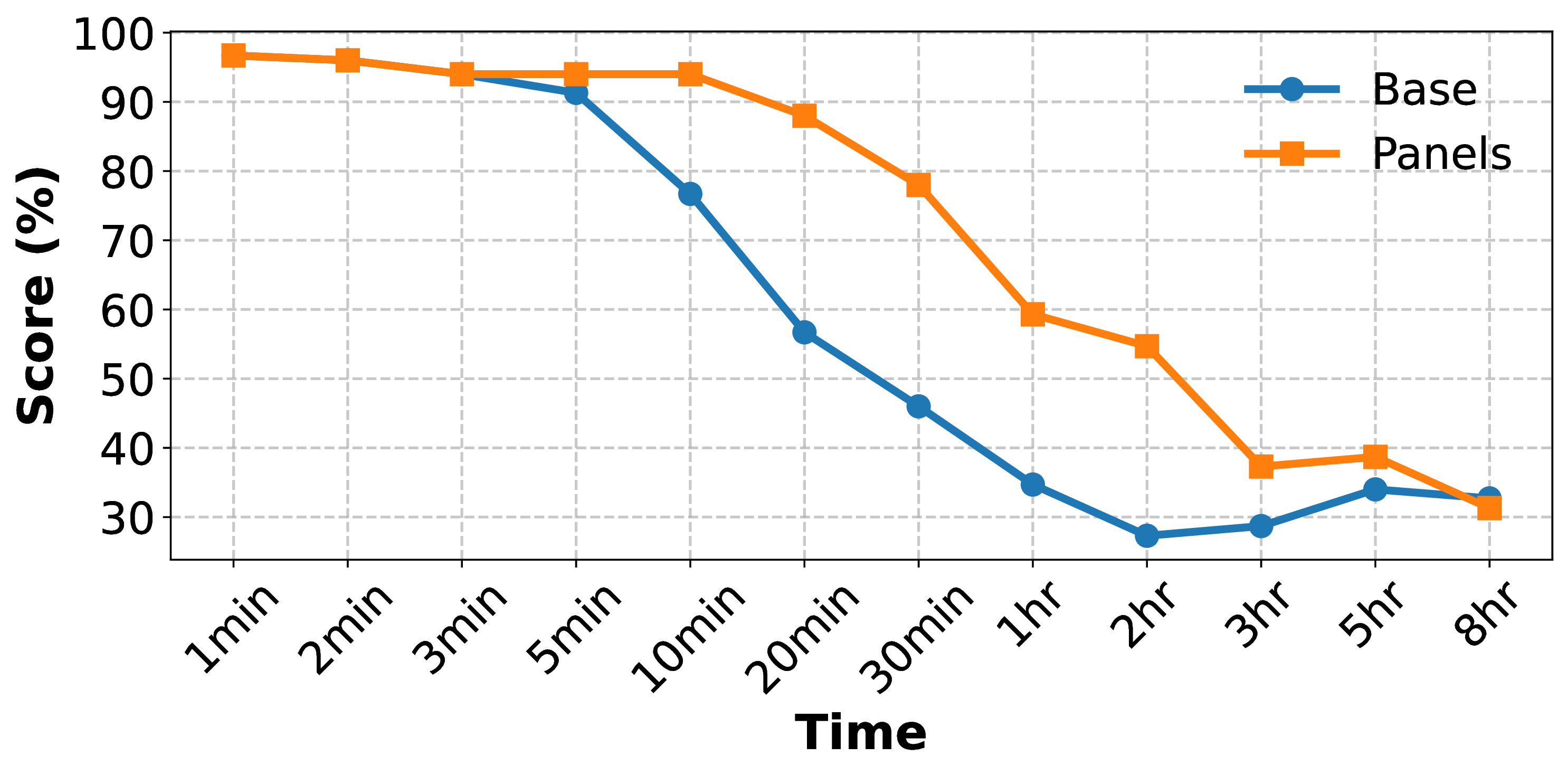
VMME Medium: ~8min 30s VMME Long: ~41min TimeScope Short: ~43min TimeScope Long: ~7h 40min
By default, this leaderboard is sorted by the Average score. To view other sorted results, please click on the corresponding header.
| # | Model | Frames | VMME (%) | TimeScope (%) | MLVU (%) |
MF2 (%) |
VNBench (%) |
Avg. (%) |
|||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Medium | Long | Overall | Short | Long | |||||||
| Small-context VLMs | |||||||||||
| 1 | Video-LLaVA 7B | 8 | 36.6 | 32.6 | 37.1 | 24.4 | 17.6 | 45.7 | 50.4 | 27.8 | 33.8 |
| 2 | + ours | 8 | 37.9 | 34.2 | 38.7 | 25.6 | 17.1 | 45.7 | 50.2 | 32.0 | 34.8 (+1.0) |
| 3 | VideoChat2-HD | 16 | 26.4 | 24.8 | 25.2 | 21.2 | 19.8 | 49.2 | 50.0 | 27.9 | 32.2 |
| 4 | + ours | 16 | 26.7 | 25.1 | 25.4 | 21.3 | 19.8 | 49.8 | 50.0 | 28.5 | 32.5 (+0.3) |
| Medium-context VLMs | |||||||||||
| 5 | LLaVA-OneVision 0.5B | 32 | 40.9 | 37.0 | 43.8 | 49.4 | 25.6 | 44.0 | 50.1 | 39.8 | 42.1 |
| 6 | + ours | 32 | 42.6 | 36.6 | 44.3 | 56.9 | 30.0 | 43.1 | 50.2 | 41.0 | 44.3 (+1.2) |
| 7 | LLaVA-OneVision 7B | 32 | 56.7 | 48.8 | 58.5 | 58.7 | 30.2 | 62.9 | 51.5 | 54.8 | 52.8 |
| 8 | + ours | 32 | 56.2 | 50.2 | 58.9 | 69.5 | 33.8 | 65.3 | 52.1 | 57.7 | 56.2 (+3.4) |
| 9 | LLaVA-OneVision 72B | 32 | 62.9 | 57.6 | 66.0 | 59.1 | 33.8 | 21.6 | 56.6 | 59.4 | 49.4 |
| 10 | + ours | 32 | 66.4 | 59.3 | 67.7 | 70.0 | 32.4 | 23.8 | 58.5 | 62.6 | 52.5 (+3.1) |
| 11 | Qwen-2.5VL 7B | 32 | 61.6 | 51.2 | 61.9 | 52.8 | 28.7 | 60.1 | 52.6 | 55.6 | 51.9 |
| 12 | + ours | 32 | 64.0 | 54.7 | 63.9 | 60.8 | 30.0 | 64.9 | 53.8 | 58.5 | 55.3 (+3.4) |
| 13 | LLaVA-Video 7B | 64 | 62.3 | 53.6 | 64.3 | 64.8 | 34.7 | 66.2 | 52.8 | -* | 56.6 |
| 14 | + ours | 64 | 62.2 | 54.0 | 64.4 | 79.2 | 39.3 | 66.0 | 54.4 | -* | 60.7 (+4.1) |
| 15 | LLaVA-Video 72B | 64 | 67.8 | 61.2 | 69.8 | 65.4 | 30.9 | 52.9 | 58.2 | -* | 55.4 |
| 16 | + ours | 64 | 68.6 | 61.4 | 70.1 | 75.7 | 30.9 | 54.4 | 59.9 | -* | 58.2 (+2.8) |
| Long-context VLMs | |||||||||||
| 17 | Qwen-2VL 7B | 180 | 62.7 | 51.0 | 62.4 | 66.1 | 23.8 | 65.7 | 54.3 | -* | 54.5 |
| 18 | + ours | 180 | 62.9 | 52.7 | 63.0 | 71.2 | 26.7 | 65.8 | 56.7 | -* | 56.7 (+2.2) |
| 19 | Qwen-2.5VL 7B | 180 | 67.6 | 54.8 | 66.0 | 73.9 | 37.6 | 66.7 | 54.2 | -* | 59.7 |
| 20 | + ours | 180 | 66.9 | 56.1 | 66.3 | 79.1 | 35.6 | 66.8 | 54.8 | -* | 60.5 (+0.8) |
| 21 | VideoLLaMA 3 7B | 180 | 64.6 | 54.1 | 65.3 | 80.2 | 39.1 | 47.3 | 58.9 | -* | 58.2 |
| 22 | + ours | 180 | 63.7 | 55.1 | 65.3 | 87.2 | 46.7 | 47.1 | 58.3 | -* | 60.9 (+2.7) |
* Since the videos of VNBench are very short, we evaluate only VLMs with up to 32 frames context on it.
Our method improves the baseline results in nearly all cases and on average across all VLMs.